
![[PyConID Talk] Introduction to Functional Programming in Python](/assets/images/python_wall.jpg)
What is Functional Programming?
Programming paradigm

The programming paradigms can be roughly divided into four categories, namely the imperative programming, where you specify do this, do that, then do this. Python is an imperative language. The second category is object oriented programming, where you model your data in the form of classes, objects and methods. Java, C++ and even Python support OOP. The third category is the logic programming paradigm, where you define some facts and relations and then query data on the basis of them. Prolog and Lisp is an example of this. The fourth category is our functional programming paradigm, where ‘function’ is the keyword to remember. Everything is done using functions.
Way of approaching problems
It is a way of approaching problems, a different way of thinking of the tasks at hand. If you have always programmed in Java, C#, Python etc., you might find it hard to write programs initially using functional programming. This is what at least happened with me!
Functions, Functions everywhere
Everything is expressed in the form of ‘functions’. Function is anything that takes an input, performs a specific task and gives out output and nothing else!!
Let’s see a simple example of “hello world”:
1
2
3
str1 = 'hello'
str2 = 'world'
print str1+' '+str2
1
2
def hello():
return 'hello world'
The first code snippet just concatenates and prints two strings, but the second code snippet returns the string from a function. Hence, the second one is clearly functional programming whereas first one is not.
Features of functional Programming
Pure Functions
Pure functions are functions without ‘side effects’. It takes an input and only input and computes the output. Side effect is anything other than just taking an input, processing it and returning an output, which includes any interaction with the outside world. In brief, it means taking something from the outside world and involving it in someway with what the function does.
Example- A function might take a global variable which means that it does not depends on only the input of the function. Printing something on the terminal or reading data from keyboard, mouse etc., where mouse and keyboard are the objects of outside world is also a side effect.
So, you want your function to take an input and only input and compute the output and return that. That’s it!
One of the key parts of functional programming is thinking as ‘purely’ as possible.
Immutability
Avoid mutability, i.e. never change the data.
Consider the example below,
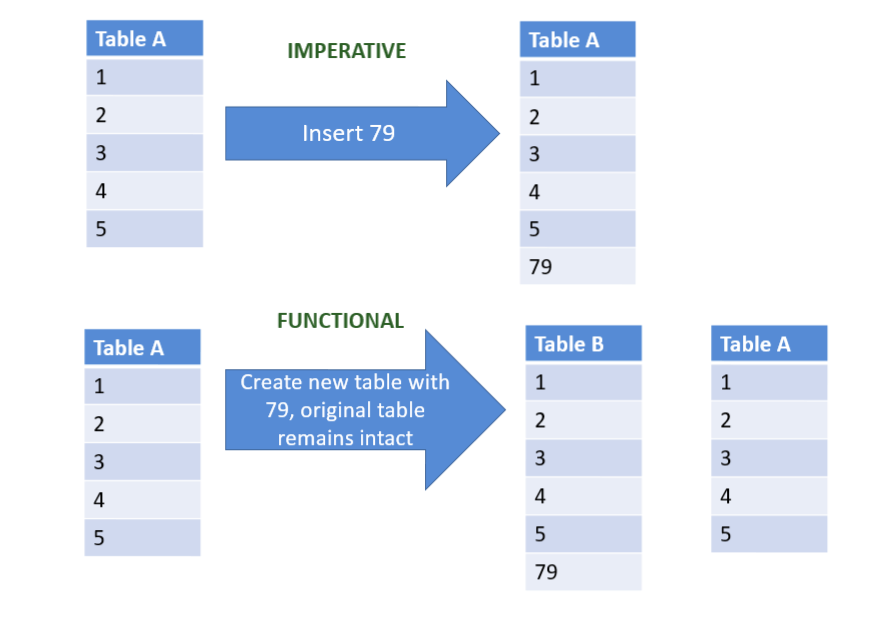
In this destructive update example, we can see that in imperative languages, the natural way to insert a value into a table is to modify the table in place, ‘which is a side effect’, because it is modifying the input. But in functional languages, you create a new version of the table while the old version is still there, which can be used for purposes of comparisons or implementing undo.
If you update the data in place and suppose you have the same data at other places as well, i.e. somewhere in other functions, this will produce the much dreaded BUGS! Oh no!
So the advantage of immutability is parallel programming, since the data remains the same always, people in teams at different geographical locations can access the data without worrying about ‘Oh, this might be changed now, i need to get the latest commit of the project!’.
Some people even think programming with dozen of cores that the CPU’s will have in future is the killer application of functional programming!
Recursion
Use recursion instead of loops and iterations since pure functional programming languages have NO LOOPS! Yes, no for loop, no while loop. But why?
Pure functional programming means programming without side effects. Which means if you write a loop, the body of the loop can’t produce side effects. Thus, if you want your loop to do something, it has to reuse the result of the previous iteration and produce something for the next iteration. This does not have a huge advantage over directly writing a recursive function for the loop.
Tail Recursion Optimization
You must have a question, if the recursion is done a large number of times, it will exhaust the space. The functional programming languages optimise recursion using TRO.
Consider this example,
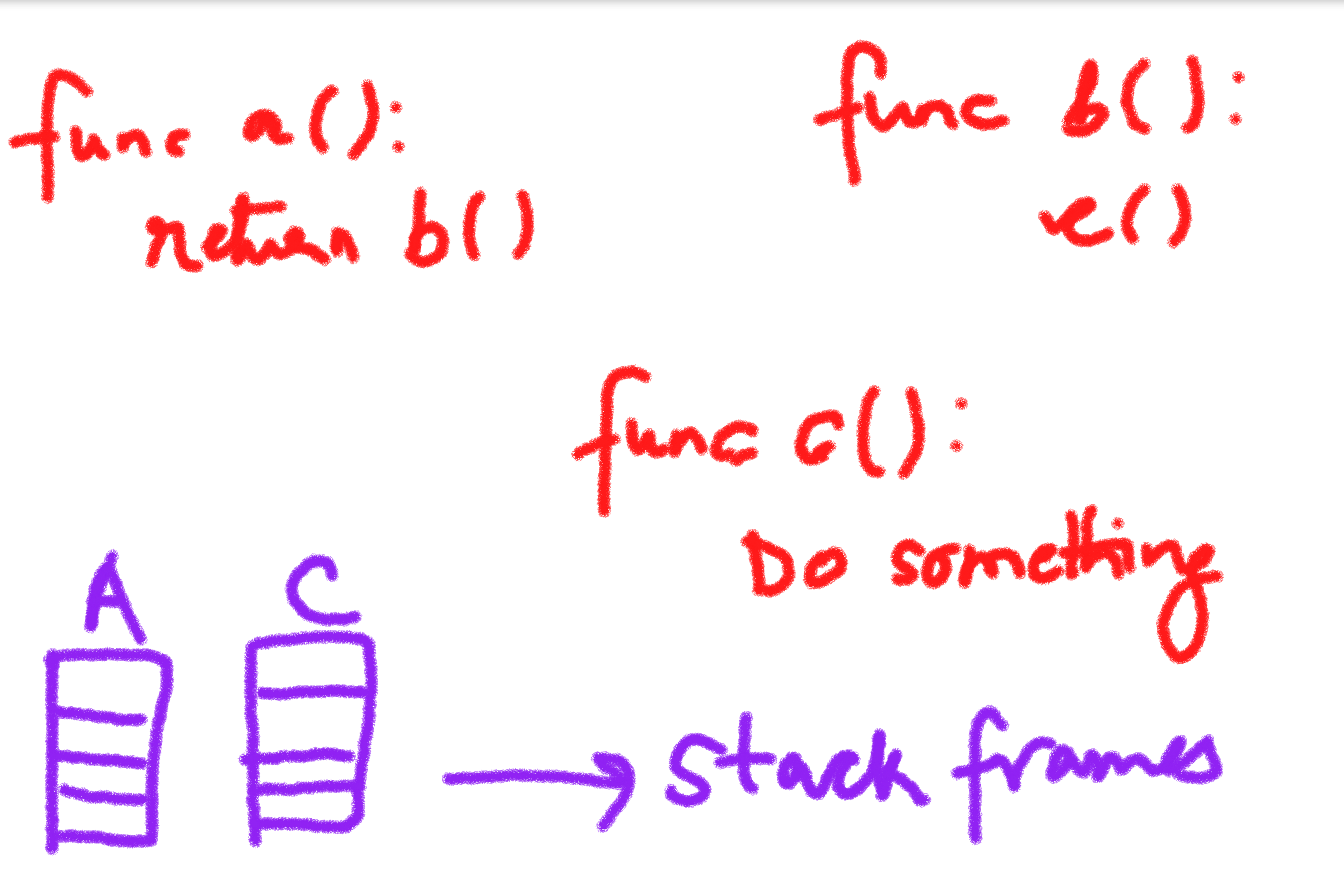
There’s this function a(), which is returning b(). However, b() is just calling c() and will return the value of c() to a(). So technically, b() is just doing the work of a mediator between a() and c(). So the stack frames for a() and c() will be made which will hold the local variables and address parameters for both the functions, but no stack frame will be made for b() because it is just calling c() and returning the value to a(). This is called last call optimisation. Tail call optimisation/ Tail recursion optimisation is a special case of last call optimisation, where the function calls itself repeatedly, therefore replacing its stack frame and not creating new ones. So even if you call a function million number of times, it will never exhaust the stack space, since it is ‘replacing’ itself each time the function is called.
So, the useful part is, because only the final result of each recursive call is needed, earlier calls don’t need to be kept on the stack. Instead of “calling itself” the function does something closer to “replacing” itself, which ends up pretty much looking like an iterative loop. This is a pretty straightforward optimization that almost all functional programming compilers generally provide.
Lazy Evaluation
Imperative programming languages follow eager evaluation, i.e. expression is evaluated as soon as it is bound to a variable. It forces the evaluation of expressions that might not be needed at run time.
But lazy evaluation means that expressions are not evaluated when they are bound to variables, but their evaluation is deferred until their results are needed by other computations. In consequence, arguments are not evaluated before they are passed to a function, but only when their values are actually used.
Fo example, consider this Haskell code snippet which computes the length of the list
1
2
len [] = 0 -- Length of empty list is 0
len (x:xs) = 1 + len xs -- Recursively call len function
x and xs both are variable where x is the head of the list and xs is the tail of the list. You can see that we have neither given any value of x nor using it anywhere in the logic, but the program will merely give the warning but compile as expected, because Haskell is a lazily evaluated language and it will not evaluate the value of x until it really needs it.

Partial application
Partial application meand freezing some of the arguments of a function
Consider this Haskell code snippet,
1
2
3
4
add :: Int -> Int -> Int
add x y = x + y
addOne = add 1
We are defining addOne with already prefixed argument of add as 1.
So if we need to compute the sum of 3+1, we would just do
1
addOne 3
We can consider this as:
1
2
> addOne 3
> (add 1) 3
Functions as ‘first class citizens’
We can assign the functions to variables, store them in data structures, pass them as arguments to other functions, and even return them as values from other functions.
How is functional programming done in Python?
Immutable Data types (String/NamedTuples/Frozenset)
Namedtuples
Tuple uses numerical indices to access its members, whereas namedtuple assigns name as well as numerical index to its members, hence preventing the errors caused by explicitly remembering the index as in tuples. Each namedtuple is represented by its own class. The arguments passed are name of the class and a string containing its elements.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from collections import namedtuple
# Arguments are name of the class and a string containing the names of the elements
Person = namedtuple('Person', 'name gender')
alisha = Person(name = 'alisha', gender = 'f')
# Fields by name
print ("Fields accessed by name are:")
print ("Name is %s and gender is %s."%(alisha.name, alisha.gender))
# Fields by index
print ("Fields accessed by index are:")
print ("Name is %s and gender is %s."%(alisha[0], alisha[1]))
# Try mutating the elements (will get error)
alisha.name = "somerandomname"
Frozenset
frozenset is an immutable version of the Python set. Once created, it cannot be modified. Due to this reason, they are used as dictionary keys as well. It can be empty or can take a single parameter which is an iterable (lists, tuples, dictionary etc.)
1
2
3
4
5
6
7
8
9
10
11
12
food = ['cake', 'burger', 'pizza']
fSet = frozenset(food)
print (fSet)
# Empty frozenset
print (frozenset())
# Try adding a new element: error
fSet.add('chocolate')
# Try removing a new element: error
fSet.remove('cake')
Functions as ‘First Class Objects’
Python’s functions are first-class objects.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
def multiply2(a):
return a*2
# Function assigned to variable
var_multiply = multiply2
print (var_multiply(2))
# Function store in data structure (list here)
test_list = [multiply2, 7, 8]
print (test_list[0](3))
# Loop over list as with normal variables
for i in test_list:
print (i)
# Function passed as argument to other functions
def add(multiply2, b):
a = multiply2(3)
return (a+b)
add(multiply2, 3)
# Return a function from another function
def greater(a, b):
def yes_greater():
return ("Oh yeah I am the bigger one! :)")
def no_greater():
return ("Oh no I am the smaller one! :(")
if a > b:
return yes_greater
else:
return no_greater
greater(5, 2)()
Higher Order Functions
Higher order functions take in other functions as the argument or can also return a function. map, filter and reduce are perhaps the most common higher order functions found in almost all programming languages.

map()
Map takes a function and a collection of items. It makes a new, empty collection, runs the function on each item in the original collection and inserts each return value into the new collection. It returns the new collection.
1
2
3
4
5
6
7
def multiply2(a):
return (a*2)
test_list = [3,5,6,7,8,9,11,12]
# Multiply every element of list by 2
return_list = list(map(multiply2, test_list))
filter()
Filter takes a function and a collection of items. It filters out all the elements of the collection for which the function returns true.
1
2
3
4
5
6
7
8
def greater_elem(a):
if a > 10:
return True
else:
return False
# Filter if elements are greater than 10
return_list = list(filter(greater_elem, test_list))
In this example we call the greater_elem() function on every element of the list and return the elements which are True for the function.
reduce()
Reduce takes a function and a sequence and applies the function continually on the sequence and returns a single value.
1
reduce(lambda x,y: x*y, [47,11,42,13])
In this example, we are calculating the product of all elements in the list. So the evaluation order works like:
1
(((47 * 11) * 42) * 13)
P.S. reduce() is a part of functools module, so call it as functools.reduce() or import reduce from functools first.
Lambda construct
The lambda helps define the functions in a one-line fashion. In fact, the lambda keyword is pretty prominent in functional programming (and not just Python), and has its roots in Lambda Calculus – one of the ‘ancestors’ of functional programming. Functions initialized with lambda can also be called anonymous functions. We aren’t really giving it a name, just defining it on-the-go and passing it as an argument.
1
2
3
4
test_list = [3,5,6,7,8,9,0]
# Multiply every element of list by 2
return_list = list(map(lambda x: x*2, test_list)) # Define the multiply by 2 function using lambda
List Comprehensions
They are faster than map. A list comprehension can be interpreted as a simple binding because there are no more mutations or reassignments. List comprehensions are directly inspired by Haskell list comprehensions. They are not lazily evaluated though.
1
[x * 2 for x in test_list]
The same function of multiplying an element by 2, we are defining using list comprehensions instead of lambda as in previous section.
Iterators and Generators
Iterators
- Iterators represent a stream of data which returns one element at a time (thus following lazy evaluation).
- It must support a next() method, which returns the next element of the stream and return StopIteration exception if there is no next element.
- Lists and dictionaries both support iteration.
- Iteratora can be materialized it using list and tuple.
- Sequence unpacking can be done if number of elements is known.
- Files also support iteration by calling the readline() method until there are no more lines in the file. readLine() is lazily evaluated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
list1 = [2,4,7]
# iter() takes an iterable and gives one element at a time
a = iter(list1)
print (a.__next__())
print (a.__next__())
print (a.__next__())
# print (a.__next__()) -will give StopIteration exception
# Materialize the iterator using lists and tuples
list2 = [3,7,8,3,8]
l = list(list2)
t = tuple(list2)
print (t)
print (l)
# Unpacking the iterator
list3 = [7,8,4]
x = iter(list3)
(a,b,c) = x
print (a,b,c)
Generators
- Generators returns iterator that returns a stream of values.
- Normal functions vs generators: When a function reaches the return statement, local variables are destroyed and the value is returned to the caller. A later call to the same function creates a new private namespace and a fresh set of local variables, whereas in a generator function, the local variables aren’t thrown away on exiting a function and we can later resume the function where it was left off. Hence, they can be thought of as ‘resumable functions’.
- Any function containing a yield keyword is a generator function.
- When we call a generator function, it doesn’t return a single value; instead it returns a generator object that supports the iterator protocol.
- On executing the yield expression, the generator outputs the value of i (see in the snippet below), similar to a return statement. On reaching a yield the generator’s state of execution is suspended and local variables are preserved. On the next call to the generator’s next() method, the function will resume executing.¶
1
2
3
4
5
6
7
8
9
10
11
12
test_list = [2,3,5,8,8]
def yield_elems(test_list):
for i in test_list:
yield i
# Return a generator
a = yield_elems(test_list)
print (type(a)) # Generator object
print(a.__next__()) # 2
print(a.__next__()) # 3
Generator Expressions
Generator expressions return an iterator and are lazily evaluated unlike list comprehensions which return a list and are eagerly evaluated. Generator Expressions are written in ‘()’ round brackets whereas list comprehensions are written in ‘[]’ brackets.
1
2
3
4
5
a = (x for x in [1,2,3,4,5] if x>2)
a.__next__() # 3
a.__next__() # 4
a.__next__() # 5
Module ‘itertools’
When we are discussing about iterators in such great depth, we definitely need functions to manipulate the iterators. Itertools has number of iterators and functions to combine several iterators.
‘itertools’ has:
- Functions that create a new iterator based on an existing iterator
- Functions for treating an iterator’s elements as function arguments
- Functions for selecting portions of an iterator’s output
- Functions for grouping an iterator’s output.
I recommend running these examples in the Python notebook here
1
2
3
4
5
6
from itertools import *
# takes an arbitrary number of iterables as input, and returns all the elements of the first iterator,
# then all the elements of the second, and so on, until all of the iterables have been exhausted.
list(chain([1,3,4,5], ['a','b','c']))
1
2
3
4
# cycle() repeats the elements infintely, creates new iterators, will have to break out of loop.
for i in cycle([2,3,4,7,7]):
print (i)
1
2
3
4
# islice() returns a stream that’s a slice of the iterator. With a single stop argument,
# it will return the first stop elements.
list(islice([4,6,7,3], 1, 3, 2))
1
2
3
4
5
list(combinations([1, 2, 3, 4, 5], 2)) # gives combination of 2 elements in a tuple
list(combinations([1, 2, 3, 4, 5], 3)) # gives combination of 3 elements in a tuple
list(permutations([1, 2, 3, 4, 5], 2)) # gives permutation of 2 elements in a tuple
list(takewhile(lambda x: x<5, [1,4,6,4,1]))
list(dropwhile(lambda x: x < 10, [1, 4, 6, 7, 11, 34, 66, 100, 1]))
The official documentation is pretty good: itertools. I recommend checking this out.
Partial Application
Partial Application is not automatically done in Python. However, the functools module provides the function partial() for the same.
1
2
3
4
5
def sweet(choice1, choice2, choice3):
print("The food I like is %s, %s, %s"%(choice1, choice2, choice3))
order_sweet = partial(sweet, choice3='ice cream')
order_sweet('muffin', 'pancake')
In this example, if I am gonna eat a sweet dish I am always selecting an ice cream no matter what, so I freeze the argument ‘ice cream’ and store the function sweet() to order_sweet with the argument choice3 as ‘ice cream’.
Recursion
We know how to do recursion in Python. Isn’t? However be careful, you cannot do recursion for a large number as Python is not tail recursive optimized.
What are the disadvantages of Functional Programming in Python?
- No tail recursion optimization
- It’s impossible to create immutable variables everytime.
- It is impossible to seperate pure and non-pure functions.
- No pattern matching.
- No automatic partial application.
Inspite of these disadvantages, it is important for a programmer to make clever use of different programming paradigms according to the use case and it is good to know various features.
Interested in learning more about functional language Haskell?? Check out this: Learn You A Haskell
This is the Python notebook link for these examples: Examples.
These are the slides: presentation.
If you have any doubts regarding this, ping me on Twitter, LinkedIn or comment below in this post. I will get back to you asap!
Thanks for reading :)